 | | |
La synthèse des protéines chez les procaryotes | ||
| |
La synthèse des protéines chez les procaryotes a été très étudiée, car elle reprend dans les grandes lignes les mécanismes développés chez les eucaryotes et chez l'homme, mais de façon beaucoup plus simple. C'est grace aux bactéries que la biologie moléculaire a pu faire d'aussi grand progrès aujourd'hui.
La strcuture d'une protéine est entièrement determinée par la séquence en acide aminée qui la constitue. Pour synthetiser une protéine, la cellule doit donc assembler les acides aminés dans un ordre exact défini pour chaque protéine. La séquence en acide aminée est codée dans la molécule d'ADN qui constitue la mémoire de la cellule. Il existe dans la nature 20 acides aminés, mais seulement 4 bases nucléiques. Tout le problème consiste donc à transformer un code à quatre éléments en une structure linéaire à 20 éléments. Cette prouesse est réalisée dans toutes les cellules en 2 étapes appelées respectivement transcription et traduction, que nous allons détailler maintenant après avoir défini auparavant ce qu'est un gène.
Avant de continuer, je doit signaler que l'ADN ne synthètise pas les protéines, il ne fait que coder l'information nécessaire. La synthèse est effectuée par tout un mécanisme enzymatique à partir des informations portées par la molécules.
L'ADN de la cellule est une molécule linéaire constituée d'un enchainement de bases nucléiques dans un ordre précis. Cette molécule, généralement unique chez les procaryotes, est capable de coder les informations nécessaires pour synthétiser plusieurs milliers de protéines différentes. Le code de ces protéine est donc disposé bout à bout sur la molécule d'ADN. Ce qui implique que l'ADN est divisé en zone, chacune correspondant à une protéine précise. Ces zones sont appelée gène. L'ADN peut ainsi être assimilé à une bande magnétique qui comporte plusieurs fichiers à la suite l'un de l'autre.
Il ne suffit pas pour synthétiser une protéine, d'avoir une molécule d'ADN. Puisque une molécule d'ADN peut coder plusieurs protéines, il faut savoir où chacune commence et où elle finit. Il faut aussi que la protéine soit synthétisée quand il faut mais pas de façon inutile. Toutes ces informations sont codées sous forme de séquence de base à l'intérieur de la molécule d'ADN. Le gène apparait donc comme une véritable fiche technique qui indique non seulement la composition de la protéine, les conditions dans lesquelles elle doit être synthétisée et où elle doit être utilisée. Souvent, ces informations de régulation prennent plus de place dans le gène que la composition de la protéine elle même.
Nous avons vu plus haut que la molécule d'ADN est constituée de deux brins complémentaires. Des expériences ont montrés que le gène est porté par un seul des deux brins. L'autre brins ne comporte aucune information, si ce n'est qu'il permet par complémentarité de resynthétiser le premier brin. Cette règle est respectée par l'ensemble des êtres vivants sauf chez les virus à ADN chez qui le génome extrémement réduit oblige à choisir leur séquence protéique de façon à utiliser les deux brins de la molécule d'ADN. D'autre part, le brin traduit en protéine est lu dans un sens bien précis, dans le sens 5' -> 3'. Ces informations de régulation sont rassemblées dans une zone qui précéde le gène et qui est appelée promoteur. Le promoteur est caractérisé par des séquences consensus, c'est à dire des séquences de nucléotides qui ne sont pas toutes identiques d'un promoteur à un autre mais qui ressemblent, à l'exception d'un ou deux nucléotides, à une séquence moyenne (consensus) appelée boite. Il existe deux boites, la boite CAAT et la boite TATA, ainsi nommées en fonction de la séquence consensus qui les caractérise.
 Une particularité dun génome des procaryotes est l'organisation des gènes en opérons. Plusieurs sont disposés à la
suite sur le brin d'ADN et tous sont contrôlés par la même zone de régulation. Tous ces gènes seront transcris sur le
même ARN message et seront traduit en protéines. Cela est un moyen simple, mis en place par les procaryotes pour assurer la synthèse
coordonnées de protéines dépendantes. On trouve ainsi dans un opéron une enzyme et ses facteurs de régulation, les enzymes
spécifiques d'une voie métabolique, etc... Les eucaryotes ne possèdent pas d'opérons, ils ont d'autres systèmes plus
complexes, mais autrement plus performants.
Une particularité dun génome des procaryotes est l'organisation des gènes en opérons. Plusieurs sont disposés à la
suite sur le brin d'ADN et tous sont contrôlés par la même zone de régulation. Tous ces gènes seront transcris sur le
même ARN message et seront traduit en protéines. Cela est un moyen simple, mis en place par les procaryotes pour assurer la synthèse
coordonnées de protéines dépendantes. On trouve ainsi dans un opéron une enzyme et ses facteurs de régulation, les enzymes
spécifiques d'une voie métabolique, etc... Les eucaryotes ne possèdent pas d'opérons, ils ont d'autres systèmes plus
complexes, mais autrement plus performants.
La molécule d'ADN est unique dans l'organisme. Ceci a deux implications : tous mécanisme qui risque d'endommager l'ADN detruirait automatiquemnt le gène en cours de traduction et la quantité de protéines qu'il est possible de synthétiser par unité de temps est réduite. Ces difficultés ont été tournée par les cellules en n'effectuant pas la traduction directement depuis l'ADN mais se servant de celui-ci pour créer plusieurs copies de travail qui elles servivont à synthétiser les protéines.
La première étape de la synthèse protéique est donc la synthèse d'une copie de la partie utile du gène. La molécule synthétisée n'est toutefois pas de l'ADN mais de l'ARN. Elle diffère de l'ADN par trois particularités :/
L'ARN qui servira de matrice est appelé ARN messager,
car il porte le message sur la structure de la protéine. Il est
différent pour chaque protéine synthétisé.
On peut noter trois particularités de cet ARN qui différe
de celui des eucaryotes, d'une part sur une molécule d'ARN, le gène
est en un seul morceau (ce détail sera approndi lors de l'etude
des gènes fragmenté des eucoaryotes), d'autre part, un ARN
peut porter plusieur gènes; au sein d'un opéron, enfin, un même gène ne peut
coder pour qu'une seule protéine, alors que les eucaryotes par le mécanisme de l'épissage peuvent coder plusieurs protéines par un
même gène.
L'ARN messager n'est toutefois pas le seul ARN synthétisé
par la cellule à partir de l'ADN. On trouve deux autres types qui
sont aussi codés par des gènes de l'ADN, mais ne seront pas
traduits en protéines : l'ARN ribosomal, qui intervient dans la
machinerie de la synthèse protéique et l'ARN de transfert
qui participe à la reconnaissance des acides aminés. Ces
deux types sont communs à toutes les protéines synthétisées.
La synthèse de l'ARN fait intervenir un ensemble protéique très complexe, la RNA synthétase. La première étape de la transcription est la reconnaissance du gène à transcrire. Cette étape fait intervenir des mécanismes variés qui dépendent de la protéine à transcrire, mais qui tous reposent sur le principe d'une protéine spécifique du ou des gène à transcrire, qui se fixe en un endroit précis de l'ADN, située dans le promoteur. Cette protéine va servir de point d'ancrage au système RNA synthétase, cette phase n'ayant lieu naturellement que si les deux boites CAAT et TATA sont présentes. Ce complexe va parcourir la molcéule d'ADN pour la lire. Elle va tout d'abord dérouler la molécule d'ADN, puis séparer les deux brins, puis assembler les bases azotées en se servant du brin complémentaire comme matrice pour aboutir à la molécule d'ARN. Derrière elle, les deux brins se réassemblent et l'ADN se réenroule. Quand la RNA synthétase rencontre le site de terminaison de gène, elle se sépare de l'ADN est l'ARN est libéré dans le cytoplasme. Souvent, plusieurs RNA synthétase peuvent parcourir le même gène simultanément, ce qui permet à partir d'un seul gène d'obtenir de multiples copies sous forme d'ARN, ce qui permettra ultérieurement de synthétiser la protéine beaucoup plus rapidement que si la traduction avait lieu directement depuis l'exemplaire unique de l'ADN.
Maintenant que l'ARN est prêt, l'étape suivante, sa traduction en protéine va pouvoir débuter.
La traduction est la synthèse de protéine à partir du message porté par la molécule d'ARN. Ce terme de traduction se justifie car il faut passer d'une succession de 4 bases azotées à une succession de 20 acides aminés. La méthode la plus simple à imaginer est de faire correspondre à chaque acide aminé une succession de bases azotées, les groupes de base azotés correspondant à chaque acides aminés se succedant sur la molécule d'ARN pour coder la séquence de la protéine. En regroupant les bases par deux, on peut ainsi coder 8 acides aminés, par 3 on dispose de 64 possibilités, ce qui est suffisant pour nos besoins. Comme il y a 20 acides aminés, on pouvait donc supposer que :
Des expériences ont montrés que la réalité est un petit peu un mélange des trois.
Les acides aminés sont bien codés par
des triplets de bases azotés et plusieurs triplet correspondent
au même acide aminés, ce qui correspond à l'hypothèse
2. Mais certains triplets ne code aucun acide aminés (hypothèse
3). Enfin, si plusieurs triplets codent pour plusieurs acides aminés,
la correspondance ne s'est pas établie au hasard. Souvent seules
les deux premières bases sont spécifiques de l'acide aminés,
la troisième étant sans importance ou au mieux seule sa nature
chimique (purique ou pyrimidique) compte. Seul pour un petit nombre
d'acide aminés, la succession exacte des bases azotés est
importante. On retrouve ainsi un code à deux bases noyés
dans le code à trois bases (hypothèse 1).
Trois triplets ne codent pour aucun acides aminés.
Cela ne signifient pas qu'ils ne servent à rien. En réalité,
ils servent de ponctuation, indiquant au mécansime de synthèse
que la fin de la protéine est atteinte. Il existe aussi un triplet
indiqué ou débute la protéine, mais le cas est beaucoup
plus complexe puiqu'il code aussi pour un acide aminé, ce qui lui
atttribue donc deux rôles.
Il est a noter que le code de correspondance entre
les triplets de bases et les acides aminés est, à de très
rares exceptions près et dans une mesure très réduite,
universel pour l'ensemble de la planète, des bactéries à
l'homme. Ce fait, plus que tous les autres milite en faveur d'une origine
commune pour tous les êtres vivants. Ce code a été
aujourd'hui élucidé et s'appelle le code génétique.
Le triplet de base azoté est le codon.
| U | C | A | G | ||
| U |
phe leu leu |
ser ser ser |
tyr stop stop |
cys stop try |
C A G |
|
|
leu leu leu |
pro pro pro |
his gln gln |
arg arg arg |
C A G |
|
|
ileu ileu met |
thr thr thr |
asn lys lys |
ser arg arg |
C A G |
|
|
val val val |
ala ala ala |
asp glu glu |
gly gly gly |
C A G |
Dans le tableau, l'ordre des bases se lit de gauche à droite. Les codons rouges sont les codons stop qui signifient au mécanisme de synthèse protéique la fin de la chaine. Le codon bleu est le codon d'initiation qui, comme on le voit, code aussi pour la méthionine.
A partir du brin d'ARN et des acides aminés, la synthèse de la protéine va s'executer en plusieurs étapes : la reconnaissance des acides aminés, l'élongation puis la maturation de la chaine protéique. Dans la plupart des ces étapes sont sous le contrôle, le rôle majeur est joué par un ARN.
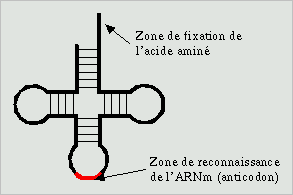 Il n'existe aucune reconnaissance directe entre un codon et un acide aminé.
Le système de synthèse des protéines reconnait les
acides aminés à ajouter à la chaine protéique
parce que ceux ci sont fixés de facon covalente à un ARN
d'un type particulier appelé ARN de transfert. Cet ARN est constitué
d'une courte chaine de base azotées à la séquence
parfaitement determiné. Cette séquence provoque un repliement
de la chaine dans l'espace qui forme alors 3 boucle et comporte une longue
queue. La seconde boucle porte la séquence complémentaire
du codon (l'anticodon) qui sera reconnu par le système de synthèse.
L'acide aminé est fixé à l'extrémité
de la longue queue au moyen d'une protéine spéciale qui reconnait
la structure tridimensionnelle de l'ARN et l'acide aminé. Il existe
20 protéines de liaison (une pour chaque acide aminé) et
61 ARN de transfert (un par codon).
Il n'existe aucune reconnaissance directe entre un codon et un acide aminé.
Le système de synthèse des protéines reconnait les
acides aminés à ajouter à la chaine protéique
parce que ceux ci sont fixés de facon covalente à un ARN
d'un type particulier appelé ARN de transfert. Cet ARN est constitué
d'une courte chaine de base azotées à la séquence
parfaitement determiné. Cette séquence provoque un repliement
de la chaine dans l'espace qui forme alors 3 boucle et comporte une longue
queue. La seconde boucle porte la séquence complémentaire
du codon (l'anticodon) qui sera reconnu par le système de synthèse.
L'acide aminé est fixé à l'extrémité
de la longue queue au moyen d'une protéine spéciale qui reconnait
la structure tridimensionnelle de l'ARN et l'acide aminé. Il existe
20 protéines de liaison (une pour chaque acide aminé) et
61 ARN de transfert (un par codon).
 La synthèse de la chaine protéique se fait dans le cytoplasme
au niveau d'un organite spécialisé, le ribosome. Le ribosome
est constitué de deux sous unités nommées 30S et 50S
en fonction de leur coefficient de sédimentation, chacune formée
de protéines et d'une troisieme sorte d'ARN, l'ARN ribosomique.
Dans un premier temps, l'ARN messager se fixe sur la particule 30S du ribosome,
au niveau du codon AUG qui indique le début de la traduction. La
deuxième sous-unité se fixe alors à la première
et reconstitue le ribosome complet et fonctionnel.
La synthèse de la chaine protéique se fait dans le cytoplasme
au niveau d'un organite spécialisé, le ribosome. Le ribosome
est constitué de deux sous unités nommées 30S et 50S
en fonction de leur coefficient de sédimentation, chacune formée
de protéines et d'une troisieme sorte d'ARN, l'ARN ribosomique.
Dans un premier temps, l'ARN messager se fixe sur la particule 30S du ribosome,
au niveau du codon AUG qui indique le début de la traduction. La
deuxième sous-unité se fixe alors à la première
et reconstitue le ribosome complet et fonctionnel.
Le ribosome comporte un site qui peut recevoir le complexe acide-aminé/ARN
de transfert. Si l'anticodon porté par l'ARNt est complémentaire
du codon de l'ARNm le complexe prend place dans le site. Le ribosome sépare
alors le complexe et soude l'acide aminé à la chaine protéique,
l'ARNt quitte le site pour être réutilisé. Le ribosome
glisse ensuite d'un codon le long de l'ARNm, pour accueillir l'acide aminé
suivant.
Quand un codon stop est rencontré, aucun complexe acide amine/ARNt
ne peut prendre place dans le site et la chaine peptidique est libérée.
Quand un ribosome a suffisament avancé le long de l'ARNm, un autre ribosome peut venir se fixer sur le site d'initiatin de la traduction et commencer une nouvelle traduction alors que la première n'est pas encore finie. Une telle structure avec plusieurs ribosomes traduisant simultanement le même ARNm est appelé polysome.
La synthèse protéiques des bactéries présente une particularité absente chez les eucaryotes, le début de la traduction alors que la transcription n'est pas terminée. Chez les eucaryotes, la synthèse d'ARN a lieu dans le noyau et les ribosomes se situant dans le cytoplasme, les deux évènements sont séparés dans l'espace et le temps. Il n'en est pas de même chez les procaryotes où les deux peuvent se prduire simultanément.
Après sa synthèse, la chaine protéique est rarement immédiatement utilisable. Elle doit subir une étape de maturation qui doit la rendre apte à exercer sa fonction. Cette étape est très variable d'une protéine à l'autre. Les principales possibilités sont :
Toutes ces étapes sont sous la dépendance de protéines spécialisées.
Tous ces mécanismes permettent la synthèse des protéine à une vitesse élevée et avec un taux d'erreur très faible. Ces mécanismes se retrouvent avec de très légères différences chez les eucaryotes.

